
I say Fake News!
Today we will use machine learning models to classify news articles as FAKE NEWS or not.
Key Imports
import numpy as np # numeric manipulation
import pandas as pd # data frame manipulation
import tensorflow as tf # machine learning
import re # regular expression
import string # string manipulation
from tensorflow import keras # machine learning
from tensorflow.keras import layers # learning layers
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras import utils # model diagram
from tensorflow.keras import losses # loss function
from sklearn.feature_extraction import text
Getting Data
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
# Drop unnecessary column
data = pd.read_csv(train_url)[["title", "text", "fake"]]
Create Data Set
We create a function that takes in a data frame and returns a Dataset object with no stop word and no puncuation.
def make_dataset(df):
# Remove stop words from text and title
stop = text.ENGLISH_STOP_WORDS
data["text"] = data["text"].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
# Construct and return a tf.data.Dataset
# with two inputs and one output
dataset = tf.data.Dataset.from_tensor_slices(
# tuple for input
( # dictionary for input data/features
{ "title": data[["title"]],
"text": data["text"]},
# dictionary for output data/labels
{ "is_fake": data[["fake"]]}
)
)
return dataset
Create and Batch the Dataset
# Batch the Dataset to increase training speed
dataset = make_dataset(data).batch(100)
Train/Validation Split
# First shuffle to eliminate any trend
dataset = dataset.shuffle(buffer_size = len(dataset))
# 20% for validation
train_size = int(0.8*len(dataset))
val_size = int(0.2*len(dataset))
train = dataset.take(train_size)
val = dataset.skip(train_size).take(val_size)
Understanding Base Rate
train_labels = np.empty(0)
for inputs, fake in train:
train_labels = np.append(train_labels, ([j[0] for j in fake["is_fake"].numpy()]))
train_labels.mean()
The “base rate” is about 52%. That is, if we simply classify every news in the training data set as fake news (is_fake = 1), then our accuracy would be 52%.
Text Vectorization
# We only keep the top 2000 ranked words (by appearance frequency)
size_vocabulary = 2000
# Function that eliminates any remaining punctuations in the text
def standardization(input_data):
no_punctuation = tf.strings.regex_replace(input_data,
'[%s]' % re.escape(string.punctuation),'')
return no_punctuation
title_vectorize_layer = TextVectorization(
standardize = standardization,
max_tokens = size_vocabulary,
output_mode = 'int',
output_sequence_length = 500)
text_vectorize_layer = TextVectorization(
standardize = standardization,
max_tokens = size_vocabulary,
output_mode = 'int',
output_sequence_length = 500)
# Let the layers "learn" from the titles/text
# from the training data set
title_vectorize_layer.adapt(train.map(lambda x, y: x["title"]))
text_vectorize_layer.adapt(train.map(lambda x, y: x["text"]))
Create Models
Model 1 - Using only Article Titles
# Specify our Title input
title_input = keras.Input(
shape=(1,),
name = "title", # SAME name as the dictionary key in the dataset
dtype = "string"
)
# Specify the layers in our model
title_features = title_vectorize_layer(title_input)
title_features = layers.Embedding(input_dim = size_vocabulary,
output_dim = 2,
name="embedding")(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.GlobalAveragePooling1D()(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.Dense(32, activation = 'relu')(title_features)
title_output = layers.Dense(2, activation = 'relu', name = "is_fake")(title_features)
title_model = keras.Model(
inputs = title_input,
outputs = title_output
)
Here is the model structure:
model = keras.Model(
inputs = [title_input, text_input],
outputs = main
)
keras.utils.plot_model(model)
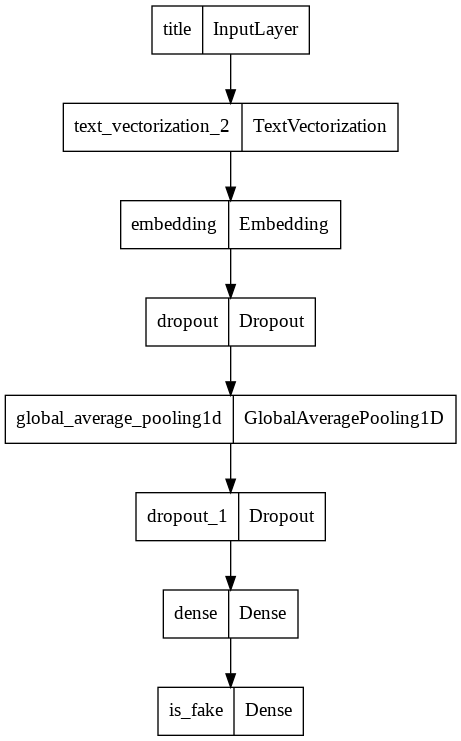
Here is the progression of training and validation accuracy. Very impressive!
Model 2 - Using only Article Text
# Specify our Title input
text_input = keras.Input(
shape=(1,),
name = "text", # SAME name as the dictionary key in the dataset
dtype = "string"
)
# Specify the layers in our model
text_features = text_vectorize_layer(text_input)
text_features = layers.Embedding(input_dim = size_vocabulary,
output_dim = 2,
name="embedding")(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation = 'relu')(text_features)
text_output = layers.Dense(2, activation = 'relu', name = "is_fake")(text_features)
text_model = keras.Model(
inputs = text_input,
outputs = text_output
)
Here is the model structure:
model = keras.Model(
inputs = [title_input, text_input],
outputs = main
)
keras.utils.plot_model(model)

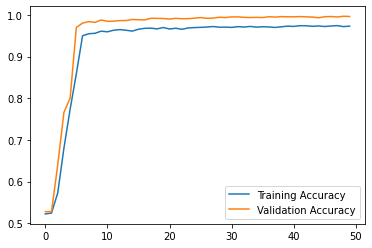
Here is the progression of training and validation accuracy.
Model 3 - Using both Article Title and Text
title_features = title_vectorize_layer(title_input)
#title_features = layers.Dropout(0.2)(title_features)
#title_features = layers.Dense(32, activation = 'relu')(title_features)
text_features = text_vectorize_layer(text_input)
#text_features = layers.Dropout(0.2)(text_features)
#text_features = layers.Dense(32, activation = 'relu')(text_features)
# Concatenate the two sets of layers that we used before
main = layers.concatenate([title_features, text_features], axis = 1)
main = layers.Embedding(input_dim = size_vocabulary * 2,
output_dim = 2,
name="embedding")(main)
main = layers.Dense(32, activation = 'relu')(main)
main = layers.GlobalAveragePooling1D()(main)
main = layers.Dropout(0.2)(main)
main = layers.Dense(64, activation = 'relu')(main)
# Append the final dense layer for classification
main = layers.Dense(2, name = "is_fake")(main)
)
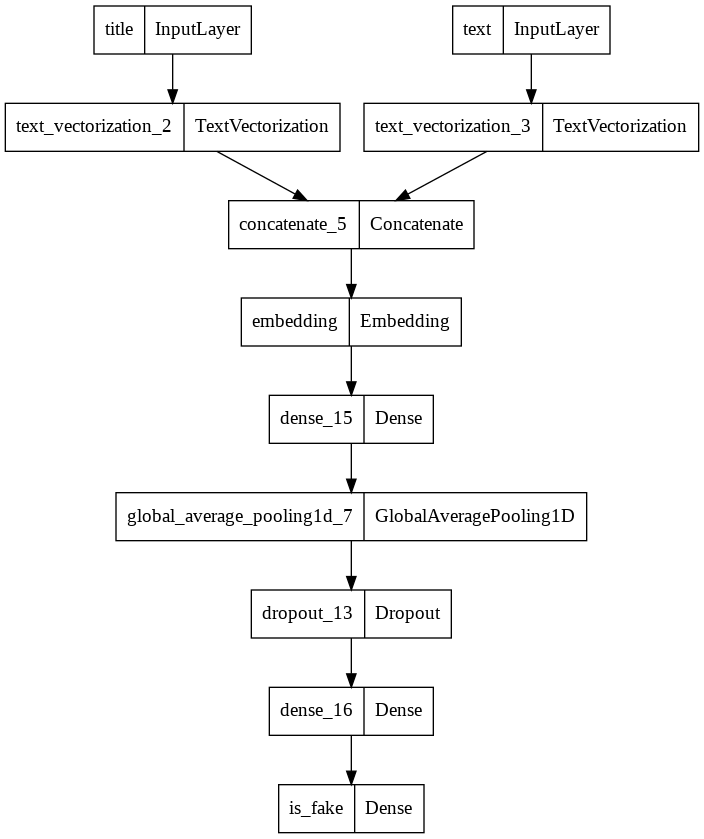
Here is the model structure:
model = keras.Model(
inputs = [title_input, text_input],
outputs = main
)
keras.utils.plot_model(model)
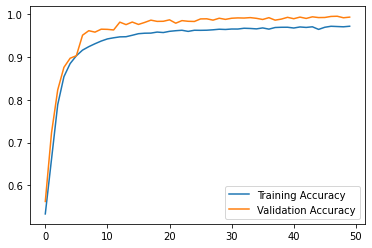
Here is the progression of training and validation accuracy.
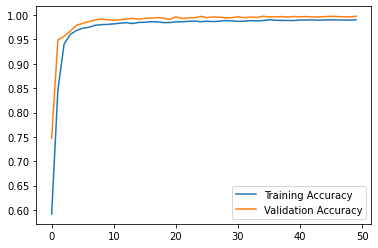
The model using both titles and texts achieved the best best validation score of about 0.9975.
Model Evaluation
# Test data
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true"
test = pd.read_csv(test_url, index_col = 0)
# Convert to dataset
test_set = make_dataset(test_data)
type(test_set)
# Evaluate our model's performance
model.evaluate(test_set)
The final test accuracy is around 0.76, which is lower than what we would have liked (and lower than that of our validation data set), but this makes sense since the test accuracy may ocntain data or insight not present in our entire training (and validation) data, thus we should expect some decrease in general prediction power.
Word Embedding
# get the weights from the embedding layer
weights = model.get_layer('embedding').get_weights()[0]
# get the vocabulary from our data prep for later
vocab = title_vectorize_layer.get_vocabulary() + text_vectorize_layer.get_vocabulary()
# Dimension reduce to 2D
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
# Loadings in df
embedding_df = pd.DataFrame({
'word' : vocab,
'x0' : weights[:,0],
'x1' : weights[:,1]
})
import plotly.express as px
fig = px.scatter(embedding_df,
x = "x0",
y = "x1",
size = [2]*len(embedding_df),
# size_max = 2,
hover_name = "word")
fig.show()
write_html(fig, "fake_news_pca.html")
I am absolutely shocked that the pca turned out so “clean” in that there are two distinct directions (it seems almost too good to be true). We observe that there are several interesting words:
- The two left-most words are “POLL”” and “TRUMP’S”, potentially referencing to headlines regarding former President Trump’s comment on issues or commenting on the ongoing election process (or post-election chaos). These words seem to indicate that the news article is “fake news”.
- The two right-most words are “agree”” and “expects”, which are two objective words that do not carry any connotation. They are most likely used in real news headlines that address world events or discussions between political leaders.
- “Race”, “Voters”, and “Inauguration” are three of the many words that are in the center. They do not immediately give us insight whether the news articles are “fake news”” or not, whih makes sense since these words, when put into different context, can most definitely create credible and rational news reporting or fanatic and attention-grabbing opinion pieces.