
Movie Recommender
Today we will recommend some movies that a user may enjoy based on common actors/actresses that appear in their favorite movie. Here is the repository: Movie Recommender
We will need scrapy to scrape actor and movie/TV show data from IMDB first, before we can do any analysis on movie recommendation. Let’s get started!
Key Imports
import scrapy # For webscraping
import pandas # For manipulating data frames
Set Up
Assuming you have everything configured in conda with properly working environment, enter terminal/console and navigate to a folder of your choice where you want to the spider scraper to be stored. Then, run the following lines, which will create a scrapy project (in a folder with all necessary files).
scrapy startproject IMDB_scraper
cd IMDB_scraper
In the file settings.py, add the following line, which will limit the amount of scraping the spider will perform. You should keep this line in while you’re initially testing the spider behavior. Once everything is all set, you may remove the line for full/maximum scraping designated by your code.
CLOSESPIDER_PAGECOUNT = 20
Scrapy spider
We wrote an ImdbSpider class which, when we run from the terminal, will access the IMDB site for the user’s favorite movie (Here we use The Dark Knight, a brilliant piece of work by Nolan), find the actors in the film, go to their pages, and scrape the films that they have acted in. This entire process is accomplished using three functions, which we detail below:
From the initial movie page
def parse(self, response):
'''
From the initial movie page, find the cast list link.
Move to that page, then call the next function:
parse_full_credits
Output: None
'''
# Find the link modifier using CSS tags, class, and attribute
to_append = response.css('a.ipc-metadata-list-item__icon-link').attrib['href']
# Append the link modifier to get the link to go to
cast_page = response.urljoin(to_append)
# Go to the Cast list page and call the next function
yield scrapy.Request(cast_page, callback = self.parse_full_credits)
Here is how this part works:
- We identify the css tag and class that correspond to the “All Cast & Crew” button “a.ipc-metadata-list-item__icon-link” and use its attribute “href” to get the underlying link modifier
- We take advantage of scrapy’s
.urljoin()to automatically join the modifier with the current link, thus giving us the full link for the next page - With
scrapy.Request(), the code simulates “clicking on and going to the ‘All Cast & Crew’” by requesting and accessing the link we just created above. - Once we are there, we will run the parse_full_credits function
From the Cast & Crew page
def parse_full_credits(self, response):
'''
From the Cast & Crew page, find every cast member's page.
Move to each of those pages and call the next function:
parse_actor_page function
Output: None
'''
# For every actor's headshot, find its underlying link to page
actor_relative_paths = [a.attrib["href"] for a in response.css("td.primary_photo a")]
# For every actor's page, move there and call the next function
for a in actor_relative_paths:
yield scrapy.Request(response.urljoin(a), callback = self.parse_actor_page)
Here is how this function works:
- From the full Cast & Crew page, we use the tag “td.primary_photo a” to locate the headshots of the cast members (credited and uncredited)
- We get the underlying link modifiers for those headshots, and take advantage of scrapy’s
.urljoin()to give us the full links for the actors’ pages to go to - With
scrapy.Request(), the code simulates “clicking on each headshot to go to every cast member’s personal IMDB pages” by requesting and accessing the links we just created above. - For every actor’s page we visit, run the parse_actor_page function
From the Actor’s personal page
def parse_actor_page(self, response):
'''
From the Cast & Crew page, find every cast member's page.
Move to each of those pages and scrape all their work as actor
Output:
A dictionary for every film on which the actor has worked
'''
# Get the actor's name
actor_name = str(response.css('h1.header span.itemprop::text')).split("data='")[-1].split("'")[0]
# Then we go to the Filmography section and find all the films
films = response.css('div.filmo-category-section div.filmo-row b a ::text').getall()
# For each film, we output a dictionary.
for film in films:
yield {"actor": actor_name, "movie_or_TV_name": film}
We’re almost there. Here’s how we gathered all the filmography data:
- First get the actor’s name
- The actor’s name is nested a few levels inside the header
- We use two tags with class specification (h1.header ; span.itemprop) to get to it
- We extract the name text without surrounding tags (::text)
- The name appears at the end of some scrapy text, so we can extract using basic text manipulation
- Then we get the films that the actor has worked on
- We access the Filmography section, then specify Actor parts only (div.filmo-category-section)
- We then get all (
.getall()) the film titles (div.filmo-row b a) and extract text only (::text)
- For every film, output a dictionary that gives the actor’s name and the film’s title
Putting Everything Together
Here is how everything fit together into the ImdbSpider class. We have specified the Dark Knight’s IMDB file link as start_urls, and we have given this class a name imdb_spider to call it in the terminal later.
After you change your working directory to the folder that contains the scrapy.cfg file, fun the following line
scrapy crawl imdb_spider -o movies.csv
Scrapy will execute the entire class that we have written and do the scraping. Without the “-o” all results will be in the forms of dictionaries (the form of output for our third function). With “-o” followed by your desired csv file name, the output will be stored as a csv file of data frame with two columns: actor and movie_or_TV_name.
class ImdbSpider(scrapy.Spider):
name = 'imdb_spider'
start_urls = ['https://www.imdb.com/title/tt0468569/']
def parse(self, response):
to_append = response.css('a.ipc-metadata-list-item__icon-link').attrib['href']
cast_page = response.urljoin(to_append)
yield scrapy.Request(cast_page, callback = self.parse_full_credits)
def parse_full_credits(self, response):
actor_relative_paths = [a.attrib["href"] for a in response.css("td.primary_photo a")]
for a in actor_relative_paths:
yield scrapy.Request(response.urljoin(a), callback = self.parse_actor_page)
def parse_actor_page(self, response):
actor_name = str(response.css('h1.header span.itemprop ::text')).split("data='")[-1].split("'")[0]
films = response.css('div.filmo-category-section div.filmo-row b a ::text').getall()
for film in films:
yield {
"actor": actor_name,
"movie_or_TV_name": film
}
Movie Recommendation
To recommend movies, we will compute a sorted list with the top movies and TV shows that share actors with the user’s favorite movie or TV show.
# Read in the csv file
movies = pd.read_csv("~/Desktop/PIC16B/Movie-Recommender/IMDB_scraper/DK_actors.csv")
# Remove duplicates in case actor is listed more than once
# for a single film on IMDB
movies.drop_duplicates(keep = 'first', inplace = True)
# Count the number of occurrences for each movie/TV show title
top_ten = movies.groupby("movie_or_TV_name").count()
# Sort the count by descending order and keep only the top ten
top_ten = top_ten.sort_values(by = "actor", axis = 0, ascending = False).head(10)
Results
It comes as no surprise that “The Dark Knight” shares the highest number of actors as itself.
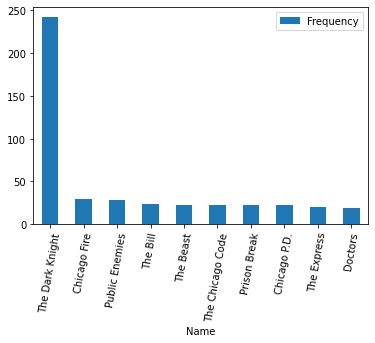
| Name | Frequency | |
|---|---|---|
| 0 | The Dark Knight | 242 |
| 1 | Chicago Fire | 29 |
| 2 | Public Enemies | 28 |
| 3 | The Bill | 24 |
| 4 | The Beast | 23 |
| 5 | The Chicago Code | 23 |
| 6 | Prison Break | 23 |
| 7 | Chicago P.D. | 22 |
| 8 | The Express | 20 |
| 9 | Doctors | 19 |
I am surprised to see that these actors have not really come together often in other films (so many stars!), but the recommended films do fit my movie preference, which is in general more action and thriller oriented. Now I know what I will be watching over the weekend :)